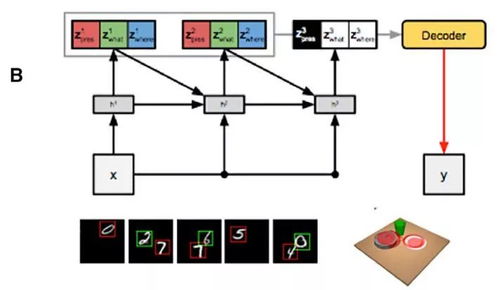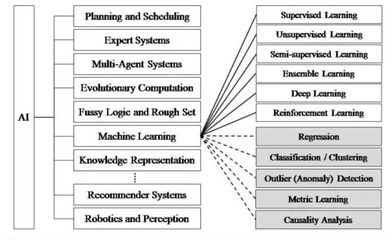
隨著生物技術與信息技術的深度融合,人工智能(AI)在新藥研發領域展現出巨大潛力,尤其是在多肽藥物分析這一前沿方向。山東大學軟件工程專業2019級的學生,在“軟件工程應用與實踐”課程中,深入探索了“基于人工智能的多肽藥物分析”這一課題,并聚焦于其核心環節——人工智能基礎軟件的開發。這一實踐項目不僅是對學生專業知識的綜合檢驗,也是對前沿科技服務生命健康的一次有益嘗試。
一、 項目背景與意義
多肽藥物因其高活性、高特異性及較低的毒副作用,已成為藥物研發的熱點。多肽序列空間龐大,其結構與功能關系復雜,傳統的實驗篩選方法耗時費力且成本高昂。人工智能技術,特別是機器學習和深度學習,能夠從海量的生物數據中學習規律,預測多肽的活性、毒性、溶解性、穩定性等關鍵性質,從而極大地加速先導化合物的發現與優化進程。
本項目的核心目標,是開發一套服務于多肽藥物分析的人工智能基礎軟件。它旨在為研究人員提供一個集數據預處理、模型構建、訓練評估和預測應用于一體的工具平臺,降低AI技術在生物醫藥領域應用的門檻。
二、 核心開發內容
軟件開發團隊遵循軟件工程規范,將項目分解為以下幾個關鍵模塊:
- 數據集成與管理模塊:從公開數據庫(如UniProt、PeptideDB)或合作實驗室獲取多肽序列及其理化、活性標注數據。開發了高效的數據清洗、標準化和特征工程(如氨基酸組成、理化性質描述符、序列編碼等)流水線,為模型訓練提供高質量輸入。
- 機器學習算法庫模塊:集成并實現了適用于多肽分析的經典機器學習算法(如支持向量機SVM、隨機森林Random Forest)以及前沿的深度學習模型(如循環神經網絡RNN、長短期記憶網絡LSTM、注意力機制模型、圖神經網絡GNN等)。模型能夠處理序列數據,并預測結合親和力、抗菌活性、細胞穿透性等多種屬性。
- 模型訓練與調優平臺:提供可視化的交互界面,允許用戶選擇數據、算法,并靈活設置超參數。平臺集成了交叉驗證、網格搜索、早停法等策略,輔助用戶高效地進行模型訓練與性能優化,自動記錄實驗過程與結果。
- 預測與可視化分析模塊:用戶輸入新的多肽序列,系統可利用訓練好的模型快速進行性質預測。結果以圖表(如活性概率分布、特征重要性排序)和報告的形式直觀呈現,輔助研究人員進行決策。
- 系統架構與部署:采用微服務架構,前后端分離。后端使用Python(TensorFlow/PyTorch, Scikit-learn框架),提供RESTful API;前端采用Vue.js等框架構建用戶友好界面。項目最終可部署于本地服務器或云端,便于協作與擴展。
三、 實踐挑戰與解決方案
在開發過程中,團隊遇到了諸多挑戰:
- 數據不均衡與噪聲:通過過采樣、欠采樣以及合成少數類過采樣技術(SMOTE)等算法進行數據平衡,并結合領域知識進行噪聲過濾。
- 模型可解釋性:集成SHAP、LIME等可解釋性AI工具,幫助生物學家理解模型的預測依據,增加結果的可信度。
- 計算資源限制:優化數據加載與模型結構,利用GPU加速訓練,并設計緩存機制提升響應速度。
- 跨學科理解:團隊成員積極與生物、藥學背景的師生溝通,確保軟件功能切實符合領域分析需求。
四、 項目成果與展望
通過本次“軟件工程應用與實踐”,團隊成功交付了一個功能相對完整、具備良好可用性的AI多肽分析基礎軟件原型。它不僅鍛煉了學生在需求分析、系統設計、算法實現、團隊協作和項目管理方面的綜合能力,更產出了具有潛在應用價值的軟件成果。
該軟件可以從以下幾方面持續深化:
- 算法深化:集成更先進的預訓練語言模型(如蛋白質語言模型),提升預測精度與泛化能力。
- 功能擴展:增加多肽從頭設計、優化建議生成等生成式AI功能。
- 生態建設:與濕實驗平臺對接,形成“計算預測-實驗驗證”的閉環,真正推動多肽藥物的發現。
###
山東大學2019級軟件工程專業的此次實踐,是“新工科”建設與“醫工結合”趨勢下的一個生動案例。它將人工智能、軟件工程與生物醫藥前沿問題緊密相連,培養了學生解決復雜跨學科實際問題的能力。所開發的“基于人工智能的多肽藥物分析基礎軟件”,既是對所學知識的創造性應用,也為人工智能賦能新藥研發貢獻了一份年輕的智慧與力量,展現了當代學子面向國家重大需求進行科技創新實踐的擔當。